论文笔记
来源:互联网 发布:开淘宝店的详细流程 编辑:程序博客网 时间:2024/06/11 21:52
一、OverFeat大框架是Hinton的Alex-net,创新点主要在以下几点:
1.训练时输入大小固定,测试时用多尺度输入;
2.没有进行对比度归一化;
3. max pooling没有采用overlap
4. 3、4、5层的feature map 比Hinton的多。
OverFeat在2013年的ImageNet上的性能表现并不是最优秀的,在18个team里面排名第5,但是他提出的测试时采用多尺度输入的idea比较
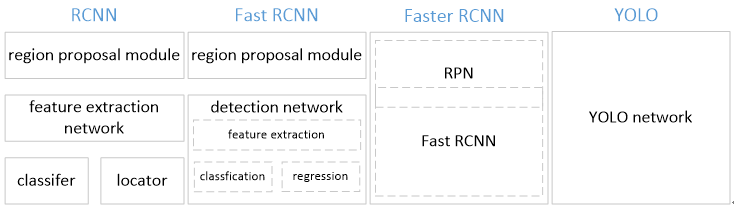
二、YOLO与rcnn、fast rcnn及faster rcnn的区别如下:
[1] YOLO训练和检测均是在一个单独网络中进行。YOLO没有显示地求取region proposal的过程。而rcnn/fast rcnn 采用分离的模块(独立于网络之外的selective search方法)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。Faster rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast rcnn的selective
search模块,将RPN集成到fast rcnn检测网络中,得到一个统一的检测网络。尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络(注意这两个网络核心卷积层是参数共享的)。
[2]
YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)。
三、YOLO9000
YOLO预测bbox的x,y,w,h,但是卷积神经网络具有平移不变性,且anchor boxes的位置被每个栅格固定,因此我们只需要通过k-means计算出anchor boxes的width和height即可,即object-class,x,y三个值我们不需要。
使用WordNet联合训练大数据集,加入多标签
图像语义分割的输出需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们需要丢弃全连接层,换上全卷积层,而这就是全卷积网络
FCN主要使用了三种技术:
卷积化(Convolutional):丢弃全连接层
上采样(Upsample):反卷积
跳跃结构(Skip Layer):因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出
主要贡献:
将端到端的卷积网络推广到语义分割中;
重新将预训练好的Imagenet网络用于分割问题中;
使用反卷积层进行上采样;
提出了跳跃连接来改善上采样的粗糙程度。
五、Deeplab
Deeplab这里使用了一个非常优雅的做法:将pooling的stride改为1,再加上 1 padding。这样池化后的图片尺寸并未减小,并且依然保留了池化整合特征的特性
因为池化层变了,后面的卷积的感受野也对应的改变了,这样也不能进行fine-tune了。所以,Deeplab提出了一种新的卷积,带孔的卷积:Atrous Convolution
六、OHEM
简单来说就是从ROI中选择hard,而不是简单的采样。
Forward: 全部的ROI通过网络,根据loss排序;
Backward:根据排序,选择B/N个loss值最大的(worst)样本来后向传播更新model的weights.
这里会有一个问题,即位置相近的ROI在map中可能对应的是同一个位置,loss值是相近的,所以针对这个问题,提出的解决方法是:对hard做nms,然后再选择B/N个ROI反向传播,这里nms选择的IoU=0.7。
在后向传播时,直觉想到的方法就是将那些未被选中的ROI的loss直接设置为0即可,但这实际上还是将所有的ROI进行反向传播,时间和空间消耗都很大,所以作者在这里提出了本文的网络框架,用两隔网络,一个只用来前向传播,另一个则根据选择的ROIs进行后向传播,的确增加了空间消耗(1G),但是有效的减少了时间消耗,实际的实验结果也是可以接受的。
- 论文笔记---小论文
- 论文笔记
- 论文笔记
- 论文笔记
- 论文笔记
- 论文阅读笔记
- 笔记-作业-论文
- 一篇可视化论文笔记
- 论文阅读笔记- Dremel
- 论文阅读笔记 - Pregel
- 论文阅读笔记1
- 论文阅读笔记2
- 论文阅读笔记3
- 论文阅读笔记4
- Zookeeper论文笔记
- 论文学习笔记:GFS
- 论文学习笔记:MapReduce
- 论文学习笔记:BigTable
- FastDfs常见错误
- jenkins全局工具配置(环境变量)
- SpringBoot之fastjson(M)
- swagger 入门(一)
- Java的变量声明_条件结构_循环
- 论文笔记
- C# 获取最新文件
- mysql 查询结构统计
- netty(九)源码分析之Future和Promise
- 实时同步MongoDB Oplog开发指南
- 有n个矩形,每个矩形可以用a,b来描述,表示长和宽。矩形X(a,b)可以嵌套在矩形Y(c,d)中当且仅当a<c,b<d或者b<c,a<d(相当于旋转X90度)。例如(1,5)可以嵌套在(6,2)内,但
- android 日历自定义控件 ,包含 阴历 和 阳历
- Android 混合音频,评价算法
- JavaSE 注解和多线程


