笔迹鉴别
来源:互联网 发布:eb病毒 知乎 编辑:程序博客网 时间:2024/06/09 19:50
http://www.cnblogs.com/zhenyulu/category/47600.html
我做的《笔迹鉴别》是与文字无关的笔迹鉴别,简单的说就是你提供给我多个人手写的“一二三四”,然后再提供给我其中一个人写的“五六七八”,我就可以通过程序判断究竟是谁写的。待识别的文字与我手头掌握的文字资料可以是不同的汉字,这就是所谓的与文字无关的笔迹鉴别。当然仅仅提供四五个汉字是不行的,需要提前准备大量的笔迹素材才可以。
我主要采用“纹理识别”的方式进行笔迹鉴别,也就是将笔迹看作是某种纹理(就像布纹、木纹一样),纹理相同的就认为是笔迹相同。而目前纹理识别我使用的是“加窗傅立叶变换”Gabor变换,利用Gabor变换提取不同频率、不同方向的笔迹特征,最后使用KNN或SVM(支持向量机)对待测样本进行类别判别。
基本步骤如下:
** 笔迹图像预处理
1、 笔迹图像扫描2、 去除稿纸中的分割线,转换成黑白二值图(目前使用PhotoShop实现)
3、 中值滤波,去除图片中的椒盐噪声(目前使用MatLab实现)
4、 倾斜校正(尽管可以使用一些现成的算法,但目前使用手工倾斜校正)
** 文字切分、纹理制作
5、 行切分、字切分(根据象素的统计信息进行切分,对于汉字中常见的左右结构以及偏旁部首等设计了偏旁部首合并策略,确保汉字的完整性。此部分自己编程实现)6、 纹理图像的制作(对切分下来的汉字将文字长、宽归一化,制作纹理图像,自己编程实现)
** Gabor变换,提取纹理特征
7、 对纹理图像进行Gabor变换(自己编程实现。由于在时域进行二维离散卷积需要大量的运算时间,因此我通过二维傅立叶变换将其转换到频域求乘法,实验表明卷积求解效率提高了近50倍),提取纹理特征(一64维向量)。8、 对Gabor变换产生的结果进行数据库存贮,以备将来识别使用(为了简便起见,我目前使用VFP,如果将来数据量再大的话,可以考虑使用SQL Server等数据库)。
** 对待测样本进行鉴别
9、 对待处理样本采用同样的处理方法提取纹理特征,然后使用KNN临近聚类的方法或SVM进行分类。(KNN自己编程实现,SVM使用现成的LibSVM。当然也有C#版的LibSVM可用来融入自己的程序中)实验表明(我只采集了9个人的笔迹),识别率可以达到91.67%以上,采取某种措施后,9人笔迹鉴别的成功率可达到100%(目前由于笔迹采集有限,才达到100%,随着笔迹样本的增加,成功率可能有所下降)。
我会在随后的文章中将以上步骤中的关键技术和关键代码放上来供大家参考。
一、文字切割
字迹在经过初始处理后,被制作成黑白二值图保存。这个步骤比较简单,可以使用PhotoShop等工具进行处理。剩下的工作就是从字迹中将一个一个的汉字摘出来,用来制作纹理图片。我采用的方法是通过字切割的方式,当然也有一些文献采用另外的较简单的方式进行处理(比如只是去掉行间、文字间的空白)。
1、行切割
对于得到的黑白二值图进行统计处理。统计黑白点阵图中每行中黑色像素的数量,得到一统计向量,该向量中极小值所对应的位置就应当是分行的地方。代码相对简单,不再赘述。
2、字切割
行切割完成后,就需要将每行中的文字切割下来,这次是对每行文字的黑色像素进行纵向统计,黑色像素数量极小的地方就有可能是分字的地方。之所以说“可能”是因为有很多汉字是左右结构(比如“朋”字),在两个“月”字中间的区域对应的黑色像素数量也很小,甚至是0,因此需要采取某种偏旁部首合并策略,将可能的左右结构汉字重新合并到一起,作为一个汉字处理。另外在进行字切割时还应当将可能是标点符号的字符去掉,防止标点符号影响字迹的识别。
我的程序中首先对初步字切割的结果进行判别,剔除标点符号。标点符号往往宽度较小,同时像素统计值比较少。然后,采用自右向左的顺序进行偏旁部首合并(之所以选择自右向左是因为汉字中左窄右宽的文字比重较大,自右向左合并的成功性较大),如果经尝试合并后的文字宽度与字迹中平均文字宽度差不多的化,就进行合并处理。
当然有时候需要进行文字切分,当发现某个切分结果过宽时,就可能预示两个汉字挨得太紧,需要进一步切分开。
经过一番文字切分、偏旁部首合并策略的的调整,我的程序能够较成功的将字迹中的文字逐一切割下来。切割结果如下图所示:

3、关键代码
在文字切割部分中用到的关键代码主要是黑白图像的读取代码。我程序中主要使用的是PixelFormat.Format1bppIndexed格式的PNG图像,一个二进制位对应一个像素点,这样比PixelFormat.Format1bppIndexed格式的BMP文件要节省磁盘空间。有关此类图像的处理技巧,可以参考:《Using the LockBits method to access image data》。这里将部分行切分时用到的代码放上来:
#region SetIndexedPixel and GetIndexedPixel for Format1bppIndexed png fileprotected void SetIndexedPixel(int x,int y,BitmapData bmd, bool pixel){ int index=y*bmd.Stride+(x>>3); byte p=Marshal.ReadByte(bmd.Scan0,index); byte mask=(byte)(0x80>>(x&0x7)); if(pixel) p |=mask; else p &=(byte)(mask^0xff); Marshal.WriteByte(bmd.Scan0,index,p);}private bool GetIndexedPixel(int x, int y, BitmapData bmd){ int index = y * bmd.Stride + (x>>3); byte p = Marshal.ReadByte(bmd.Scan0,index); byte mask=(byte)(0x80>>(x&0x7)); if(((int)(p & mask))== 0) return true; else return false;}#endregionprivate void CalcBlackDotsOfLine(){ Bitmap bm = new Bitmap(this.ImageFileName); BlackDotsOfLine = new int[bm.Height]; BitmapData bmdn=bm.LockBits(new Rectangle(0,0,bm.Width,bm.Height), ImageLockMode.ReadOnly, PixelFormat.Format1bppIndexed); for(int y=0; y < bm.Height; y++) for(int x=0; x < bm.Width; x++) if(this.GetIndexedPixel(x, y, bmdn)) BlackDotsOfLine[y]++; bm.UnlockBits(bmdn);}之所以使用LockBits方法是因为这样处理速度比较快,如果速度并不是很重要的因素的话,我建议使用Bitmap对象的SetPixel方法和GetPixel方法。
二、纹理制作
1、纹理制作
文字切割完成后,就需要制作纹理图像了。我这里主要参考了“刘宏 李锦涛 崔国勤 唐胜,基于SVM和纹理的笔迹鉴别方法,计算机辅助设计与图形学学报,Vol15(12),pp1479-1484”一文,将文字缩放至16×16点阵大小,并拼接成384×384规格的图片,每幅图片可以切割成9个128×128大小的图片作为训练样本。待测样本制作成256×256大小,可以切割成4个128×128大小的纹理图片。下面是一张训练样本图片和两张待测样本图片:

训练样本(384×384大小)


待测样本(256×256大小)
纹理制作好后就可以使用Gabor变换程序进行变换提取笔迹特征了。Gabor变换将在下一部分再做介绍。
2、关键代码
纹理制作过程中的关键代码主要是图像的缩放操作,将切割下来的文字缩放成16×16点阵并且进行拼接。这方面的资料很多,包括博客园在内的很多网站在对大图片进行显示之前都要进行尺寸处理。我这里将我程序中的关键代码放上来(略经删截):
private void BeginProcess(){ Image imgSrc = this.spbSrc.PicBox.Image, imgDest; Rectangle destRect, srcRect; if(this.cboSize.SelectedIndex == 0) imgDest = new Bitmap(384, 384, PixelFormat.Format24bppRgb); else imgDest = new Bitmap(256, 256, PixelFormat.Format24bppRgb); Graphics g = Graphics.FromImage(imgDest); g.CompositingQuality = CompositingQuality.HighSpeed; g.SmoothingMode = SmoothingMode.HighSpeed; g.InterpolationMode = InterpolationMode.Bilinear; int current = 0; for(int y=0; y < imgDest.Height; y+=CharSize) for(int x = 0; x < imgDest.Width; x+=CharSize) { destRect = new Rectangle(x, y, CharSize, CharSize); srcRect = (Rectangle)CharsRectangle[current]; g.DrawImage(imgSrc, destRect, srcRect, GraphicsUnit.Pixel); }}其中CharSize是一常量,值为16。
一、二维卷积运算
Gabor变换的本质实际上还是对二维图像求卷积。因此二维卷积运算的效率就直接决定了Gabor变换的效率。在这里我先说说二维卷积运算以及如何通过二维傅立叶变换提高卷积运算效率。在下一步分内容中我们将此应用到Gabor变换上,抽取笔迹纹理的特征。
1、离散二维叠加和卷积
关于离散二维叠加和卷积的运算介绍的书籍比较多,我这里推荐William K. Pratt著,邓鲁华 张延恒 等译的《数字图像处理(第3版)》,其中第7章介绍的就是这方面的运算。为了便于理解,我用下面几个图来说明离散二维叠加和卷积的求解过程。

A可以理解成是待处理的笔迹纹理,B可以理解成Gabor变换的核函数,现在要求A与B的离散二维叠加卷积,我们首先对A的右边界和下边界填充0(zero padding),然后将B进行水平翻转和垂直翻转,如下图:

然后用B中的每个值依次乘以A中相对位置处的值并进行累加,结果填入相应位置处(注意红圈位置)。通常二维卷积的结果比A、B的尺寸要大。如下图所示:

2、快速傅立叶变换卷积
根据傅立叶变换理论,对图像进行二维卷积等价于对图像的二维傅立叶变换以及核函数的二维傅立叶变换在频域求乘法。通过二维傅立叶变换可以有效提高卷积的运算效率。但在进行傅立叶变换时一定要注意“卷绕误差效应”,只有正确对原有图像以及卷积核填补零后,才能得到正确的卷积结果。关于这部分内容可以参考William K. Pratt著,邓鲁华 张延恒 等译的《数字图像处理(第3版)》第9章的相关内容,此处就不再赘述。
目前网上可以找到开源C#版的快速傅立叶变换代码(Exocortex.DSP),我使用的是1.2版,2.0版似乎只能通过CVS从SourceForge上签出, 并且功能没有什么太大改变。将Exocortex.DSP下载下来后,将源代码包含在自己的项目中,然后就可以利用它里面提供的复数运算以及傅立叶变换功能了。为了测试通过傅立叶变换求卷积的有效性,特编写以下代码:
using System;using Exocortex.DSP;class MainEntry{ static void Main() { fftConv2 c = new fftConv2(); c.DoFFTConv2(); }}public class fftConv2{ double[,] kernel = {{-1, 1}, {0, 1}}; double[,] data = {{10,5,20,20,20}, {10,5,20,20,20}, {10,5,20,20,20}, {10,5,20,20,20}, {10,5,20,20,20}}; Complex[] Kernel = new Complex[8*8]; Complex[] Data = new Complex[8*8]; Complex[] Result = new Complex[8*8]; private void Init() { for(int y=0; y<2; y++) for(int x=0; x<2; x++) Kernel[y*8+x].Re = kernel[y,x]; for(int y=0; y<5; y++) for(int x=0; x<5; x++) Data[y*8+x].Re = data[y,x]; } public void DoFFTConv2() { Init(); Fourier.FFT2(Data, 8, 8, FourierDirection.Forward); Fourier.FFT2(Kernel, 8, 8, FourierDirection.Forward); for(int i=0; i<8*8; i++) Result[i] = Data[i] * Kernel[i] / (8*8); Fourier.FFT2(Result, 8, 8, FourierDirection.Backward); for(int y=0; y<6; y++) { for(int x=0; x<6; x++) Console.Write("{0,8:F2}", Result[y*8+x].Re); Console.WriteLine(); } }}程序的运行结果与离散二维叠加和卷积的运算结果完全相同。
由于卷积结果与原始输入图片的大小是不一样的,存在着所谓“边界”,在我的实际应用程序中,为了避免这些“边界”对结果过多的影响,我采用的是居中阵列定义,并且从卷积结果中只截取需要的那部分内容,确保和原始图片的大小完全一致,如下图:
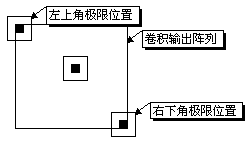
这就需要对卷积的傅立叶求法做些微小的调整,具体调整办法就不说了,主要是坐标的变换,将示例代码贴上来供大家参考:
using System;using Exocortex.DSP;class MainEntry{ static void Main() { CenterfftConv2 s = new CenterfftConv2(); s.CommonMethod(); s.DoFFTConv2(); }}public class CenterfftConv2{ double[,] kernel = {{0, 1, 0}, {1, 2, 0}, {0, 0, 3}}; double[,] data = new double[12,12]; Complex[] Kernel = new Complex[16*16]; Complex[] Data = new Complex[16*16]; Complex[] Result = new Complex[16*16]; public CenterfftConv2() { Random r = new Random(); for(int y=0; y<12; y++) for(int x=0; x<12; x++) data[y,x] = r.NextDouble(); for(int y=0; y<3; y++) for(int x=0; x<3; x++) Kernel[y*16+x].Re = kernel[y,x]; for(int y=1; y<13; y++) for(int x=1; x<13; x++) Data[y*16+x].Re = data[y-1,x-1]; } public void DoFFTConv2() { Console.WriteLine(" ========= By FFT2Conv2 Method ========="); Fourier.FFT2(Data, 16, 16, FourierDirection.Forward); Fourier.FFT2(Kernel, 16, 16, FourierDirection.Forward); for(int i=0; i<16*16; i++) Result[i] = Data[i] * Kernel[i] / (16*16); Fourier.FFT2(Result, 16, 16, FourierDirection.Backward); for(int y=2; y<14; y++) { for(int x=2; x<14; x++) Console.Write("{0,5:F2}", Result[y*16+x].GetModulus()); Console.WriteLine(); } } public void CommonMethod() { double real = 0; Console.WriteLine(" ========== Direct Transform ==========="); for(int y=0; y < 12; y++) { for(int x=0; x < 12; x++) { for(int y1=0; y1 < 3; y1++) for(int x1=0; x1 < 3; x1++) { // (kernel.Length-1)/2 = 1 if(((y - 1 + y1)>=0) && ((y - 1 + y1)<12) && ((x - 1 + x1)>=0) && ((x - 1 + x1)<12)) { real += data[y - 1 + y1, x - 1 + x1] * kernel[2 - x1, 2 - y1]; } } Console.Write("{0,5:F2}", real); real=0; } Console.WriteLine(); } Console.WriteLine("\n"); }}有了此部分的基础知识后,我们就要步入笔迹识别中最核心的部分Gabor变换,提取笔迹的特征了。
二、Gabor函数
Gabor变换属于加窗傅立叶变换,Gabor函数可以在频域不同尺度、不同方向上提取相关的特征。另外Gabor函数与人眼的生物作用相仿,所以经常用作纹理识别上,并取得了较好的效果。二维Gabor函数可以表示为:

其中:
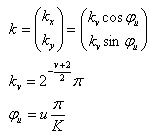
v的取值决定了Gabor滤波的波长,u的取值表示Gabor核函数的方向,K表示总的方向数。参数![]() 决定了高斯窗口的大小,这里取
决定了高斯窗口的大小,这里取![]() 。程序中取4个频率(v=0, 1, ..., 3),8个方向(即K=8,u=0, 1, ... ,7),共32个Gabor核函数。不同频率不同方向的Gabor函数可通过下图表示:
。程序中取4个频率(v=0, 1, ..., 3),8个方向(即K=8,u=0, 1, ... ,7),共32个Gabor核函数。不同频率不同方向的Gabor函数可通过下图表示:



图片来源:GaborFilter.html

图片来源:http://www.bmva.ac.uk/bmvc/1997/papers/033/node2.html
三、代码实现
Gabor函数是复值函数,因此在运算过程中要分别计算其实部和虚部。代码如下:
private void CalculateKernel(int Orientation, int Frequency){ double real, img; for(int x = -(GaborWidth-1)/2; x<(GaborWidth-1)/2+1; x++) for(int y = -(GaborHeight-1)/2; y<(GaborHeight-1)/2+1; y++) { real = KernelRealPart(x, y, Orientation, Frequency); img = KernelImgPart(x, y, Orientation, Frequency); KernelFFT2[(x+(GaborWidth-1)/2) + 256 * (y+(GaborHeight-1)/2)].Re = real; KernelFFT2[(x+(GaborWidth-1)/2) + 256 * (y+(GaborHeight-1)/2)].Im = img; }}private double KernelRealPart(int x, int y, int Orientation, int Frequency){ double U, V; double Sigma, Kv, Qu; double tmp1, tmp2; U = Orientation; V = Frequency; Sigma = 2 * Math.PI * Math.PI; Kv = Math.PI * Math.Exp((-(V+2)/2)*Math.Log(2, Math.E)); Qu = U * Math.PI / 8; tmp1 = Math.Exp(-(Kv * Kv * ( x*x + y*y)/(2 * Sigma))); tmp2 = Math.Cos(Kv * Math.Cos(Qu) * x + Kv * Math.Sin(Qu) * y) - Math.Exp(-(Sigma/2)); return tmp1 * tmp2 * Kv * Kv / Sigma; }private double KernelImgPart(int x, int y, int Orientation, int Frequency){ double U, V; double Sigma, Kv, Qu; double tmp1, tmp2; U = Orientation; V = Frequency; Sigma = 2 * Math.PI * Math.PI; Kv = Math.PI * Math.Exp((-(V+2)/2)*Math.Log(2, Math.E)); Qu = U * Math.PI / 8; tmp1 = Math.Exp(-(Kv * Kv * ( x*x + y*y)/(2 * Sigma))); tmp2 = Math.Sin(Kv * Math.Cos(Qu) * x + Kv * Math.Sin(Qu) * y) - Math.Exp(-(Sigma/2)); return tmp1 * tmp2 * Kv * Kv / Sigma; }有了Gabor核函数后就可以采用前文中提到的“离散二维叠加和卷积”或“快速傅立叶变换卷积”的方法求解Gabor变换,并对变换结果求均值和方差作为提取的特征。32个Gabor核函数对应32次变换可以提取64个特征(包括均值和方差)。由于整个变换过程代码比较复杂,这里仅提供测试代码供下载。该代码仅计算了一个101×101尺寸的Gabor函数变换,得到均值和方差。代码采用两种卷积计算方式,从结果中可以看出,快速傅立叶变换卷积的效率是离散二维叠加和卷积的近50倍。
代码下载请点 >>>> 这里 。注意,代码中没有包含Exocortex.DSP,请测试者到相应网站上下载并包含在自己的项目中。
解压缩后,里面有一"GaborTest.png"文件,程序中默认路径是“D:\”,请将此图片放置到此路径下。(程序代码在Visual Studio .net 2003下调试通过)。
一、k-NN法
这种概率密度函数估计的方法是这样的:在以特征向量x为中心的一个邻域里,固定落入邻域中的样本的个数k(n)。这可以通过下面的方法实现:在一个合适的距离尺度下,逐渐增大包围x点的区域体积,直到有k个样本点落入这个区域中。这就是x周围离它最近的k(n)个样本。在这k(n)个样本中,数量最多的种类就可以看作样本x的类型。当然k的选取也很重要。随着k的增加,k-NN的错误率将逐渐贴近贝叶斯错误率。
在进行k-NN聚类之前首先要对Gabor变换的结果数据归一化,以确保结果运算的有效性。具体说就是让每个测量数据的取值在[0, 1]或[-1, 1]之间。举例来说:假设有两类数据,一类数据的中心位于坐标(-1, 10000)处,另一类数据的中心位于(0,9996)处,有一待测样本,坐标值是(-1,9997),它应当属于拿类呢?如果计算欧氏距离的化,该样本属于第二类。但仔细分析可知,该样本应当属于第一类,因为纵坐标的值过于大(其实待测样本的纵坐标只比训练样本有万分之几的变化,完全可以忽略不计)。现在我们将纵坐标缩小10000倍,归一到[-1, 1]上,则两类待测样本坐标变为(-1,1)和(0,0.9996),待测样本坐标为(-1,0.9997),显然属于第一类。
至于k-NN的代码实现相对来说比较简单。我采用了链表的方式。链表为有序定长的链表,设x为待测样本,依次计算x与p个训练样本的距离(我采用的是欧氏距离)。将该结果依次和链表中各元素比较,如果小于某一节点,则将新结果插入到该节点之前,并删除链表中最后一个节点。这样,当完成x与所有p个训练样本的距离计算后,链表中就记录了和它最近的k个样本。我们通过判别这k个样本中数量最多的种类完成对x类型的估计。
代码相对简单,这里就不再占用空间贴代码了。下面我们看看SVM分类。
二、SVM
SVM分类器通常具有较高的分类精度。我这里不想过多的去说SVM是怎么回事,只是提供一种使用SVM进行判别的方法。我使用的是开源的LibSVM实现SVM分类。Google上输入LIBSVM可以很容易的找到代码下载。我使用的是C#版(不过是2.6版),也可以使用C++的2.81版。下面我说说如何使用2.81版中带的编译好的程序完成聚类工作。该版本支持多类判别。
1、数据准备工作
首先对Gabor变换结果进行处理,生成符合SVM处理规范的文本格式。关于格式的更多说明可以参考软件使用手册。另外此步可以不用归一化,因为LibSVM工具中提供了scale工具,可以自动完成数据的归一化处理工作。
2、程序配置工作
LibSVM 2.81版下载下来后并不能直接操作,还需要一些辅助工作,否则在默认判别的方式下工作判别精度可能非常低。关于此方面的更多内容可以参考《A Practical Guide to Support Vector Classification》一文,该PDF文档可以从LibSVM的网站上下载到。
在使用LibSVM之前首先要安装Pathon,Pathon 2.4可以从Pathon的网站上下载到。
紧接着就是需要装“pgnuplot.exe”,LibSVM使用它完成参数搜索时的绘图工作,该程序没有包含在LibSVM 2.81版的压缩包中,需要自己到网上搜索并下载。另外在LibSVM 2.81中grid.py代码里默认pgnuplot.exe的路径是“c:\tmp\gnuplot\bin\pgnuplot.exe”,你可以将“pgnuplot.exe”放到该路径下或修改grid.py代码指向你自己的路径。
所有这些准备工作完成后,就可以进行SVM分类工作了。
3、SVM分类
使用SVM分类可以执行“libsvm-2.81\tools”目录下的easy.py程序,该程序提供了一套默认的、精度较高的SVM分类算法。
在DOS窗口下输入:C:\Python\Python easy.py Train.txt Test.txt就可以利用Train.txt中的数据进行训练,然后对Test.txt中的数据进行判别。
*** 结果 ***
本人采集了多人的笔迹,经过纹理制作、Gabor变换提取出了相应的特征。在使用KNN与SVM对待测样本进行聚类时均取得了较高的识别精度。通过优化,10人笔迹的测试精度可以达到100%,效果还是很不错的。
2006年2月
======= 全文完 =======
- 笔迹鉴别
- 笔迹
- 笔迹
- 笔迹心理学
- 笔迹心理学
- 听写笔迹
- android 记录笔迹 顾客签名笔迹
- psp鉴别
- 手机鉴别
- 蜂蜜鉴别
- JAVA学习笔迹1
- 光笔笔迹跟踪算法
- 学习jquery笔迹
- 笔迹心理学(2): 功能设计
- 笔迹心理学(3): 界面设计
- C++学习笔迹
- 无线传感网络笔迹
- 【性能】笔迹书写延时
- DataGridView输入验证
- 对intent的初步了解
- 管理仅有公平是不够的
- 遇拒不恼,受恭不喜——普适大众才是公平规则
- 转至windows核心编程 线程的基础知识
- 笔迹鉴别
- 找到正在使用temp file的session
- 与世界同步的危险
- AT&T 官方解锁iPhone 4 (无需升级最新操作系统) 操作步骤
- Combobox三级联动
- TCPCopy 把在线流量导入到测试系统中
- 先把“制造”做好
- VC++.Net的代码折叠
- iOS开发——图片转PDF的实现方法


