集成学习实践(sklearn)
来源:互联网 发布:孝子之至 莫大乎尊亲 编辑:程序博客网 时间:2024/06/08 03:59
1 Random Forest和Gradient Tree Boosting参数详解
在sklearn.ensemble库中,我们可以找到Random Forest分类和回归的实现:RandomForestClassifier和RandomForestRegression,Gradient Tree Boosting分类和回归的实现:GradientBoostingClassifier和GradientBoostingRegression。有了这些模型后,立马上手操练起来?少侠请留步!且听我说一说,使用这些模型时常遇到的问题:
1、明明模型调教得很好了,可是效果离我的想象总有些偏差?——模型训练的第一步就是要定好目标,往错误的方向走太多也是后退。
2、凭直觉调了某个参数,可是居然没有任何作用,有时甚至起到反作用?——定好目标后,接下来就是要确定哪些参数是影响目标的,其对目标是正影响还是负影响,影响的大小。
3、感觉训练结束遥遥无期,sklearn只是个在小数据上的玩具?——虽然sklearn并不是基于分布式计算环境而设计的,但我们还是可以通过某些策略提高训练的效率。
4、模型开始训练了,但是训练到哪一步了呢?——饱暖思淫欲啊,目标,性能和效率都得了满足后,我们有时还需要有别的追求,例如训练过程的输出,袋外得分计算等等。
通过总结这些常见的问题,我们可以把模型的参数分为4类:目标类、性能类、效率类和附加类。下表详细地展示了4个模型参数的意义:

不难发现,基于bagging的Random Forest模型和基于boosting的Gradient Tree Boosting模型有不少共同的参数,然而某些参数的默认值又相差甚远。在《使用sklearn进行集成学习——理论》一文中,我们对bagging和boosting两种集成学习技术有了初步的了解。Random Forest的子模型都拥有较低的偏差,整体模型的训练过程旨在降低方差,故其需要较少的子模型(n_estimators默认值为10)且子模型不为弱模型(max_depth的默认值为None),同时,降低子模型间的相关度可以起到减少整体模型的方差的效果(max_features的默认值为auto)。另一方面,Gradient Tree Boosting的子模型都拥有较低的方差,整体模型的训练过程旨在降低偏差,故其需要较多的子模型(n_estimators默认值为100)且子模型为弱模型(max_depth的默认值为3),但是降低子模型间的相关度不能显著减少整体模型的方差(max_features的默认值为None)。
2 如何调参?
聪明的读者应当要发问了:”博主,就算你列出来每个参数的意义,然并卵啊!我还是不知道无从下手啊!”
参数分类的目的在于缩小调参的范围,首先我们要明确训练的目标,把目标类的参数定下来。接下来,我们需要根据数据集的大小,考虑是否采用一些提高训练效率的策略,否则一次训练就三天三夜,法国人孩子都生出来了。然后,我们终于进入到了重中之重的环节:调整那些影响整体模型性能的参数。
2.1 调参的目标:偏差和方差的协调
同样在集成学习理论中,我们已讨论过偏差和方差是怎样影响着模型的性能——准确度。调参的目标就是为了达到整体模型的偏差和方差的大和谐!进一步,这些参数又可分为两类:过程影响类及子模型影响类。在子模型不变的前提下,某些参数可以通过改变训练的过程,从而影响模型的性能,诸如:“子模型数”(n_estimators)、“学习率”(learning_rate)等。另外,我们还可以通过改变子模型性能来影响整体模型的性能,诸如:“最大树深度”(max_depth)、“分裂条件”(criterion)等。正由于bagging的训练过程旨在降低方差,而boosting的训练过程旨在降低偏差,过程影响类的参数能够引起整体模型性能的大幅度变化。一般来说,在此前提下,我们继续微调子模型影响类的参数,从而进一步提高模型的性能。
2.2 参数对整体模型性能的影响
假设模型是一个多元函数F,其输出值为模型的准确度。我们可以固定其他参数,从而对某个参数对整体模型性能的影响进行分析:是正影响还是负影响,影响的单调性?
对Random Forest来说,增加“子模型数”(n_estimators)可以明显降低整体模型的方差,且不会对子模型的偏差和方差有任何影响。模型的准确度会随着“子模型数”的增加而提高。由于减少的是整体模型方差公式的第二项,故准确度的提高有一个上限。在不同的场景下,“分裂条件”(criterion)对模型的准确度的影响也不一样,该参数需要在实际运用时灵活调整。调整“最大叶节点数”(max_leaf_nodes)以及“最大树深度”(max_depth)之一,可以粗粒度地调整树的结构:叶节点越多或者树越深,意味着子模型的偏差越低,方差越高;同时,调整“分裂所需最小样本数”(min_samples_split)、“叶节点最小样本数”(min_samples_leaf)及“叶节点最小权重总值”(min_weight_fraction_leaf),可以更细粒度地调整树的结构:分裂所需样本数越少或者叶节点所需样本越少,也意味着子模型越复杂。一般来说,我们总采用bootstrap对样本进行子采样来降低子模型之间的关联度,从而降低整体模型的方差。适当地减少“分裂时考虑的最大特征数”(max_features),给子模型注入了另外的随机性,同样也达到了降低子模型之间关联度的效果。但是一味地降低该参数也是不行的,因为分裂时可选特征变少,模型的偏差会越来越大。在下图中,我们可以看到这些参数对Random Forest整体模型性能的影响:
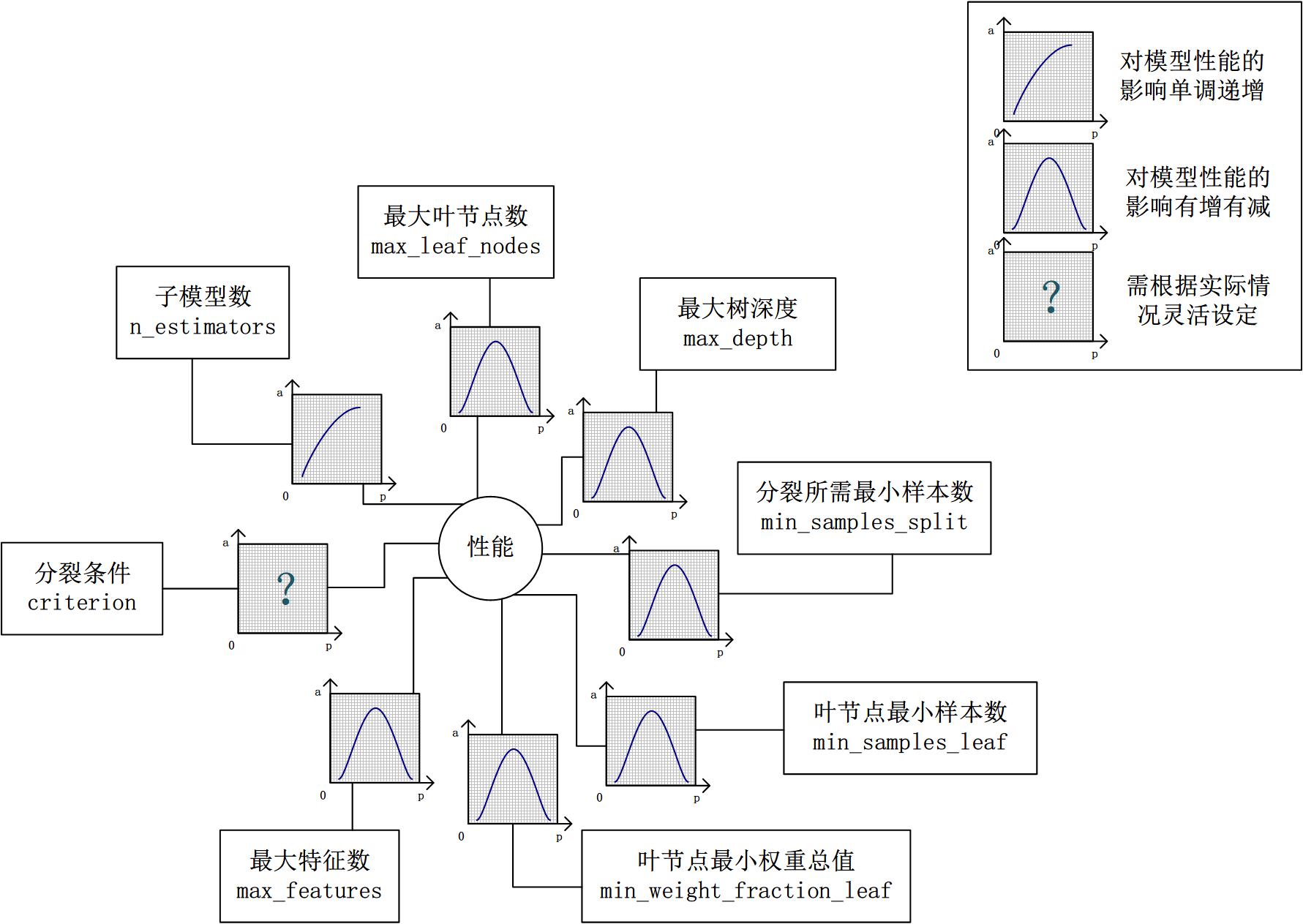
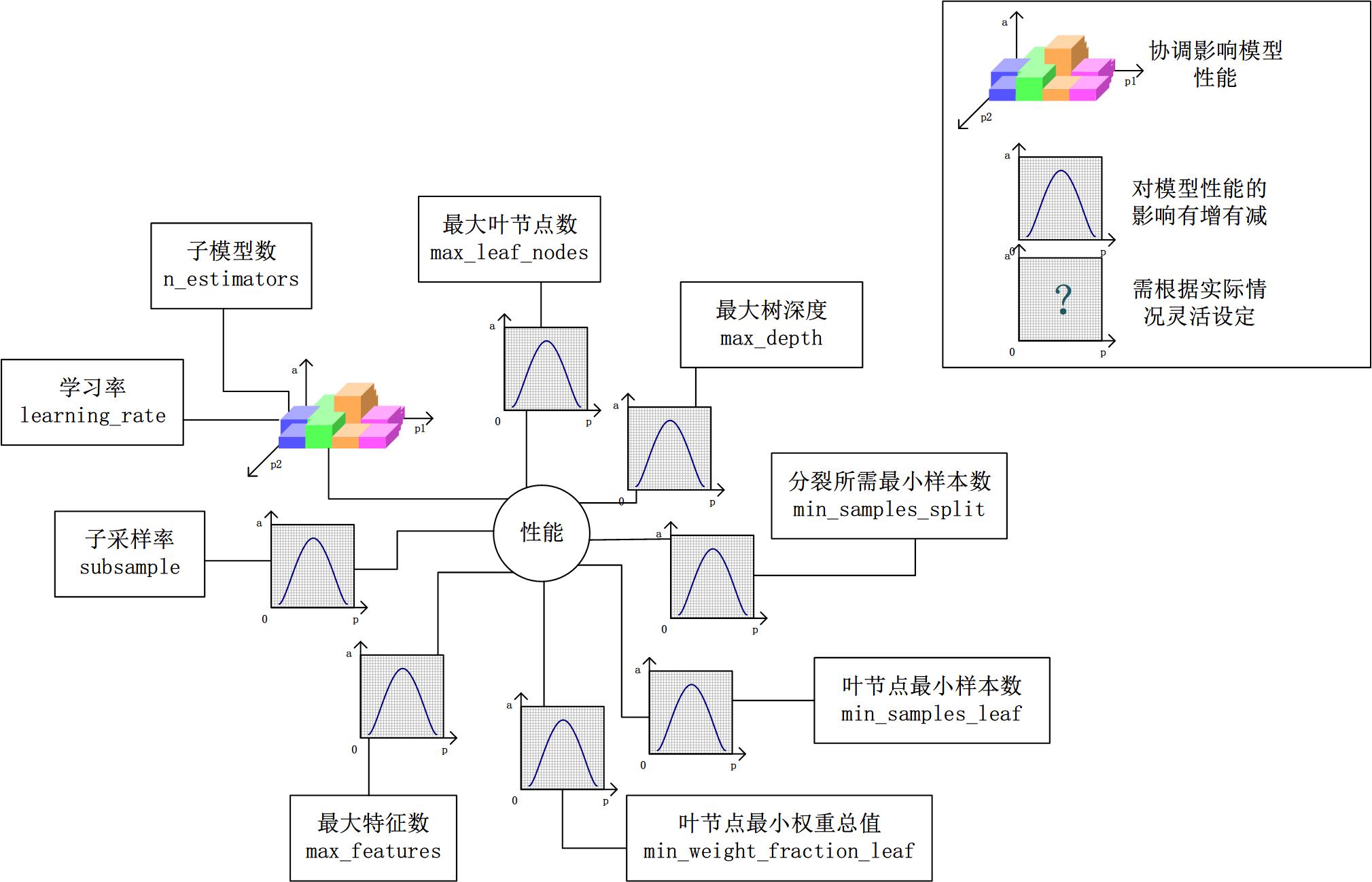
2.3 一个朴实的方案:贪心的坐标下降法
到此为止,我们终于知道需要调整哪些参数,对于单个参数,我们也知道怎么调整才能提升性能。然而,表示模型的函数F并不是一元函数,这些参数需要共同调整才能得到全局最优解。也就是说,把这些参数丢给调参算法(诸如Grid Search)咯?对于小数据集,我们还能这么任性,但是参数组合爆炸,在大数据集上,或许我的子子孙孙能够看到训练结果吧。实际上网格搜索也不一定能得到全局最优解,而另一些研究者从解优化问题的角度尝试解决调参问题。
坐标下降法是一类优化算法,其最大的优势在于不用计算待优化的目标函数的梯度。我们最容易想到一种特别朴实的类似于坐标下降法的方法,与坐标下降法不同的是,其不是循环使用各个参数进行调整,而是贪心地选取了对整体模型性能影响最大的参数。参数对整体模型性能的影响力是动态变化的,故每一轮坐标选取的过程中,这种方法在对每个坐标的下降方向进行一次直线搜索(line search)。首先,找到那些能够提升整体模型性能的参数,其次确保提升是单调或近似单调的。这意味着,我们筛选出来的参数是对整体模型性能有正影响的,且这种影响不是偶然性的,要知道,训练过程的随机性也会导致整体模型性能的细微区别,而这种区别是不具有单调性的。最后,在这些筛选出来的参数中,选取影响最大的参数进行调整即可。
无法对整体模型性能进行量化,也就谈不上去比较参数影响整体模型性能的程度。是的,我们还没有一个准确的方法来量化整体模型性能,只能通过交叉验证来近似计算整体模型性能。然而交叉验证也存在随机性,假设我们以验证集上的平均准确度作为整体模型的准确度,我们还得关心在各个验证集上准确度的变异系数,如果变异系数过大,则平均值作为整体模型的准确度也是不合适的。
- 集成学习实践(sklearn)
- 使用sklearn进行集成学习——实践
- 使用sklearn进行集成学习——实践
- 使用sklearn进行集成学习——实践
- 使用sklearn进行集成学习——实践
- 使用sklearn进行集成学习(一)
- 使用sklearn进行集成学习(二)
- sklearn中集成学习(下)
- 使用sklearn进行机器学习—实践
- 系列 《使用sklearn进行集成学习——理论》 《使用sklearn进行集成学习——实践》 目录 1 Random Forest和Gradient Tree Boosting参数详解 2 如何调参?
- 使用sklearn进行集成学习——理论
- 使用sklearn进行集成学习——理论
- 利用sklearn进行集成学习之相关理论
- 利用sklearn进行集成学习之调参
- 使用sklearn进行集成学习——理论
- 使用sklearn进行集成学习——理论
- 集成学习理论(sklearn)
- sklearn学习
- #129 Rehashing
- SSH中后端获取到的数据传向页面显示
- C语言基础知识
- APP二次启动问题
- BZOJ1110: [POI2007]砝码Odw
- 集成学习实践(sklearn)
- servlet利用拦截器改写request和response
- pycharm——快捷键、常用设置、配置管理
- UICollectionView基础
- 剑指Offer_45_扑克牌顺子
- angularjs的自定义directive指令的绑定策略scope:”@”、”=”、”&”
- JavaScript 中的 this !
- react native中如何查找realm默认的文件default.realm
- Why is epoll faster than select?


