再论EM算法的收敛性和K-Means的收敛性
来源:互联网 发布:淘宝网男士长袖t恤 编辑:程序博客网 时间:2024/05/20 01:34
标签(空格分隔): 机器学习
(最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性。在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝马迹,下次不要再掉坑啊。。)
EM算法的收敛性
1.通过极大似然估计建立目标函数:
通过EM算法来找到似然函数的极大值,思路如下:
希望找到最好的参数
如下图所示: 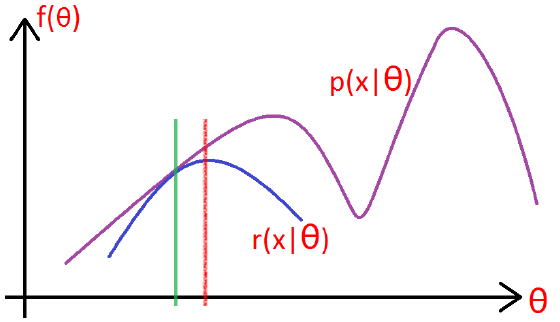
- 在绿色线位置,找到一个
γ 函数,能够使得该函数最接近目标函数,- 固定
γ 函数,找到最大值,然后更新θ ,得到红线;
- 固定
- 对于红线位置的参数
θ :- 固定
θ ,找到一个最好的函数γ ,使得该函数更接近目标函数。
重复该过程,直到收敛到局部最大值。
- 固定
2. 从Jensen不等式的角度来推导
令
(对于log函数的Jensen不等式)
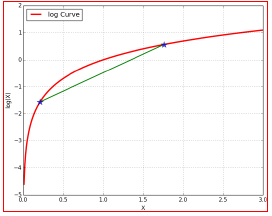
3.使等号成立的Q
尽量使
对于EM的目标来说:应该使得
也就是分子的联合概率与分母的z的分布应该成正比,而由于
故
4.EM算法的框架
由上面的推导,可以得出EM的框架: 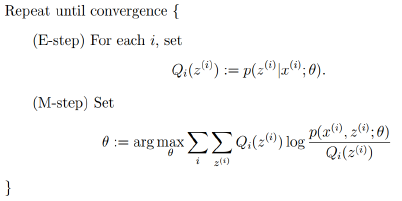
回到最初的思路,寻找一个最好的
* E-step: 根据当前的参数
* M-step: 对于当前找到的
K-Means的收敛性
通过上面的分析,我们可以知道,在EM框架下,求得的参数
目标函数
假设使用平方误差作为目标函数:
E-Step
固定参数
M-Step
固定数据点的分配,更新参数(中心点)
所以,答案有了吧。为啥K-means会收敛呢?目标是使损失函数最小,在E-step时,找到一个最逼近目标的函数
- 再论EM算法的收敛性和K-Means的收敛性
- EM算法收敛性的推导
- EM算法收敛性的相关资料
- 为什么研究算法的收敛性
- 迭代算法的收敛性
- EM算法(算法原理+算法收敛性)
- 肯普纳级数收敛性的证明
- Blockchain的鱼和熊掌系列(一)收敛性分析
- 梯度下降算法收敛性
- BBR算法及其收敛性
- k-means和EM算法的Matlab实现
- 关于瑕点型反常积分的收敛性判别
- 从TCP拥塞本质看BBR算法及其收敛性(附CUBIC的改进/NCL机制)
- K-means聚类算法背后的EM思想
- 感知机的收敛性(Novikoff定理)证明(原创)
- K-means与EM的关系
- EM算法结合k-means
- K-Means聚类和EM算法复习总结
- Java之多线程锁
- 策略模式【Strategy Pattern】
- 关于flask中文件下载的实例
- ARP协议解析
- JS加PHP动态倒计时(定时器)
- 再论EM算法的收敛性和K-Means的收敛性
- flv文件格式解析
- C#正则表达式
- NHibernate实践之----事务
- pdf转jpg的在线与用转换器的转换方法
- spring boot 学习--08---搭建ssmm-01
- SVN的子命令SVN merge详解,应用两组源文件的差别到工作拷贝路径
- C读取lua表
- 球的体积微分公式


