Linux内存管理中内存的组织及主要数据结构分析(pg_data_t&&page&&zone)
来源:互联网 发布:社交网络达人 编辑:程序博客网 时间:2024/06/09 17:40
在讲解内核中用于组织内存的数据结构之前,考虑到术语不总是容易理解,所以先来看看几个概念。我们首先考虑NUMA系统,这样,在UMA系统上介绍这些概念就非常容易了。
下图给出内存划分的图示:
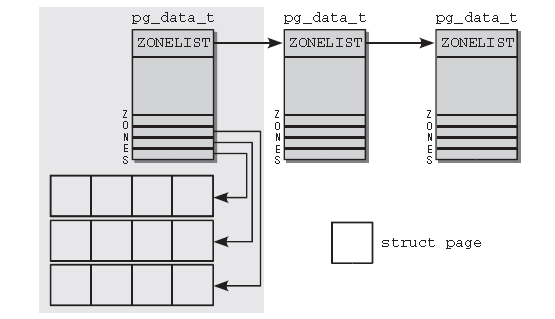
首先,内核划分为结点。每个结点关联到系统中的一个处理器,在内核中表示为pa_data_t的实例(稍后定义该数据结构)。各个结点又划分为内存域,是内存的进一步细分。例如,对可用于(ISA设备的)DMA操作的内存区是有限制的。只有钱16MB适用,还有一个高端内存区无法直接映射,在二者之间是通用的“普通”内存区。内核引入下列常量来枚举系统中的所有内存域:
enum zone_type {#ifdef CONFIG_ZONE_DMAZONE_DMA,//标记适合DMA的内存域。该区域的长度依赖于处理器的类型。在IA-32计算机上,一般的限制是16MB,这是由古老的ISA设备强加的边界,但更现代的计算机也可能受这一限制的影响#endif#ifdef CONFIG_ZONE_DMA32ZONE_DMA32,//标记了使用32位地址字可寻址、适合DMA的内存域。显然只有在64位系统上两种DMA内存域才有差别。在32位系统上本内存域是空的。#endifZONE_NORMAL,//标记了可直接映射的内核段的普通内存域。这是在所有体系结构上保证都会存在的唯一内存域,但无法保证该地址范围对应了实际的物理内存。例如,如果AMD64系统有2G内存,那么所有内存都属于ZONE_DMA32范围,而ZONE_NORMAL则为空。#ifdef CONFIG_HIGHMEMZONE_HIGHMEM,//标记了超出内核段的物理内存。#endifZONE_MOVABLE,//它是一个虚拟内存域,在防止物理内存碎片的机制中需要使用该内存域,我会在后面的文章中讲解。MAX_NR_ZONES//充当结束标记。在内核想要迭代系统中所有内存域时,会用到该变量。};各个内存域都关联了一个数组,用来阻止属于该内存域的物理内存页(在内核中称之为页帧)。对每个页帧,都分配了一个struct page实例以及所需的管理数据。各个内存结点都保存在一个单链表中,供内核遍历。处于性能考虑,在为进程分配内存时,内核总是试图在当前运行的CPU相关联的NUMA结点上进行。但这并不总是可行的,例如,该结点的内存可能已经用尽。对此情况,每个结点都提供了一个备用列表(借助于struct zonelist)。该列表包含了其他结点(和相关的内存域),可用于代替当前结点分配内存,列表项的位置越靠后,就越不适合分配。在UMA系统上,上图中只有一个pg_data_t结点,其他的都不变。
主要数据结构分析:
struct pg_data_t详细分析:
typedef struct pglist_data {struct zone node_zones[MAX_NR_ZONES];//是一个数组,包含了结点中各内存域的数据结构struct zonelist node_zonelists[MAX_ZONELISTS];//指点了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存int nr_zones;//保存结点中不同内存域的数目#ifdef CONFIG_FLAT_NODE_MEM_MAPstruct page *node_mem_map;//指向page实例数组的指针,用于描述结点的所有物理内存页,它包含了结点中所有内存域的页。#endifstruct bootmem_data *bdata;//在系统启动期间,内存管理子系统初始化之前,内核页需要使用内存(另外,还需要保留部分内存用于初始化内存管理子系统)。为解决这个问题,内核使用了前面文章讲解的自举内存分配器。<span style="font-family: Arial;">bdata指向自举内存分配器数据结构的实例。</span>#ifdef CONFIG_MEMORY_HOTPLUGspinlock_t node_size_lock;#endifunsigned long node_start_pfn;//该NUMA结点第一个页帧的逻辑编号。系统中所有的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一)。unsigned long node_present_pages; //结点中页帧的数目unsigned long node_spanned_pages;//该结点以页帧为单位计算的长度,包含内存空洞。int node_id;//全局结点ID,系统中的NUMA结点都从0开始编号wait_queue_head_t kswapd_wait;//交换守护进程的等待队列,在将页帧换出结点时会用到。后面的文章会详细讨论。struct task_struct *kswapd;//指向负责该结点的交换守护进程的task_struct。int kswapd_max_order;//定义需要释放的区域的长度。} pg_data_t;struct zone详细分析:
struct zone {/* Fields commonly accessed by the page allocator */unsigned longpages_min, pages_low, pages_high;//如果空闲页多于pages_high,则内存域的状态时理想的;如果空闲页的数目低于pages_low,则内核开始将页换出到硬盘;如果空闲页低于pages_min,那么页回收工作的压力就比较大,因为内核中急需空闲页。/* * We don't know if the memory that we're going to allocate will be freeable * or/and it will be released eventually, so to avoid totally wasting several * GB of ram we must reserve some of the lower zone memory (otherwise we risk * to run OOM on the lower zones despite there's tons of freeable ram * on the higher zones). This array is recalculated at runtime if the * sysctl_lowmem_reserve_ratio sysctl changes. */unsigned longlowmem_reserve[MAX_NR_ZONES];//分别为各种内存域指定了若干页,用于一些无论如何都不能失败的关键性内存分配。#ifdef CONFIG_NUMAint node;/* * zone reclaim becomes active if more unmapped pages exist. */unsigned longmin_unmapped_pages;unsigned longmin_slab_pages;struct per_cpu_pageset*pageset[NR_CPUS];#elsestruct per_cpu_pagesetpageset[NR_CPUS];//这个数组用于实现每个CPU的热/冷页帧列表。内核使用这些列表来保存可用于满足实现的“新鲜”页。但冷热页帧对应的高速缓存状态不同:有些页帧很可能在高速缓存中,因此可以快速访问,故称之为热的;未缓存的页帧与此相对,称之为冷的。#endif/* * free areas of different sizes */spinlock_tlock;#ifdef CONFIG_MEMORY_HOTPLUG/* see spanned/present_pages for more description */seqlock_tspan_seqlock;#endifstruct free_areafree_area[MAX_ORDER];//用于实现伙伴系统,每个数组元素都表示某种固定长度的一些连续内存区,对于包含在每个区域中的空闲内存页的管理,free_area是一个起点。#ifndef CONFIG_SPARSEMEM/* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */unsigned long*pageblock_flags;#endif /* CONFIG_SPARSEMEM */ZONE_PADDING(_pad1_)//这一部分涉及的结构成员,用来根据活动情况对内存域中使用的页进行编目,如果页访问频繁,则内核认为它是活动的;而不活动的页则显然相反。在需要换出页时,这种区别是很重要的,如果可能的话,频繁使用的页应该保持不动,而多余的不活动的页则可以换出而没有什么影响。spinlock_tlru_lock;struct list_headactive_list;//活动页的集合struct list_headinactive_list;//不活动页的集合unsigned longnr_scan_active;//在回收内存时,需要扫描的活动页的数目unsigned longnr_scan_inactive;//在回收内存时,需要扫描的不活动页的数目unsigned longpages_scanned;//指定了上次换出一页一来,有多少页未能成功扫描unsigned longflags;//描述了内存域的当前状态/* Zone statistics */atomic_long_tvm_stat[NR_VM_ZONE_STAT_ITEMS];//维护了大量有关该内存域的统计信息/* * prev_priority holds the scanning priority for this zone. It is * defined as the scanning priority at which we achieved our reclaim * target at the previous try_to_free_pages() or balance_pgdat() * invokation. * * We use prev_priority as a measure of how much stress page reclaim is * under - it drives the swappiness decision: whether to unmap mapped * pages. * * Access to both this field is quite racy even on uniprocessor. But * it is expected to average out OK. */int prev_priority;//存储了上一次扫描操作扫描该内存域的优先级ZONE_PADDING(_pad2_)/* Rarely used or read-mostly fields *//* * wait_table-- the array holding the hash table * wait_table_hash_nr_entries-- the size of the hash table array * wait_table_bits-- wait_table_size == (1 << wait_table_bits) * * The purpose of all these is to keep track of the people * waiting for a page to become available and make them * runnable again when possible. The trouble is that this * consumes a lot of space, especially when so few things * wait on pages at a given time. So instead of using * per-page waitqueues, we use a waitqueue hash table. * * The bucket discipline is to sleep on the same queue when * colliding and wake all in that wait queue when removing. * When something wakes, it must check to be sure its page is * truly available, a la thundering herd. The cost of a * collision is great, but given the expected load of the * table, they should be so rare as to be outweighed by the * benefits from the saved space. * * __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the * primary users of these fields, and in mm/page_alloc.c * free_area_init_core() performs the initialization of them.*///一下三个变量实现了一个等待队列,可用于等待某一页变为可用的进程,进程排成一个队列,等待某些条件,在条件变为真时,内核会通知进程恢复工作。wait_queue_head_t* wait_table;unsigned longwait_table_hash_nr_entries;unsigned longwait_table_bits;/* * Discontig memory support fields. */struct pglist_data*zone_pgdat;//建立内存域和父结点之间的关联/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */unsigned longzone_start_pfn;//内存域第一个页帧的索引/* * zone_start_pfn, spanned_pages and present_pages are all * protected by span_seqlock. It is a seqlock because it has * to be read outside of zone->lock, and it is done in the main * allocator path. But, it is written quite infrequently. * * The lock is declared along with zone->lock because it is * frequently read in proximity to zone->lock. It's good to * give them a chance of being in the same cacheline. */unsigned longspanned_pages;//指定内存域中页的总数,但并非所有的都可用,因为有空洞unsigned longpresent_pages;//指定了内存域中实际上可用的页数目/* * rarely used fields: */const char*name;//保存该内存域的惯用名称,目前有3个选项可用NORMAL DMA HIGHMEM}____cacheline_internodealigned_in_smp;该结构比较特殊的方面是它由ZONE_PADDING分割为几个部分。这是因为对zone结构的访问非常频繁。在多处理器系统上,通常会有不同的CPU试图同时访问结构成员。因此使用锁(后面的博客会详细介绍)防止它们彼此干扰,避免错误和不一致。由于内核对该结构的访问非常频繁,因此会经常性地获取该结构的两个自旋锁zone->lock和zone->lru_lock。如果数据保存在CPU高速缓存中,那么会处理得更快速。高速缓存分为行,每一行负责不同的内存区。内核使用ZONE_PADDING宏生成“填充”字段添加到结构中,以确保每个自旋锁都处于自身的缓存行中。还使用了编译关键字__cacheline_internodealigned_in_smp,用以实现最优的高速缓存对齐方式。
该结构的最后两个部分也通过填充字段彼此分隔开来。两者都不包含锁,主要目的是将数据保持在一个缓存行中,便于快速访问,从而无需从内存加载数据。由于填充字段造成结构长度的增加是可以忽略的,特别是在内核内存中zone结构的实例相对很少。
struct page详细分析:
struct page {unsigned long flags;//存储了体系结构无关的标志,用于描述页的属性atomic_t _count;//是一个使用计数,表示内核中应用该页的次数。在其值到达0时,内核就知道page实例当前不使用,因此可以删除;如果其值大于0,该实例绝不会从内存删除。union {atomic_t _mapcount;//内存管理子系统中映射的页表项计数,表示在页表中有多少项指向该页unsigned int inuse;//用于SLUB分配器,对象的数目};union { struct {unsigned long private;//是一个指向“私有”数据的指针,虚拟内存管理会忽略该数据。根据页的用途,可以用不用的方式使用该指针,大多数情况下它用于将页与缓冲区关联起来。struct address_space *mapping;//mapping默认情况下是指向address_space的,但如果使用技巧将其最低位置1,mapping就指向anon_vma对象 };#if NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS spinlock_t ptl;#endif struct kmem_cache *slab;//用于SLUB分配器,指向slab的指针 struct page *first_page;//用于复合页的尾页,指向首页};union {pgoff_t index;//在映射内的偏移量void *freelist;/* SLUB: freelist req. slab lock */};struct list_head lru;//是一个表头,用于在各种链表上维护该页,一遍将页按不用类别分组,最重要的类别是活动页和不活动页/* * On machines where all RAM is mapped into kernel address space, * we can simply calculate the virtual address. On machines with * highmem some memory is mapped into kernel virtual memory * dynamically, so we need a place to store that address. * Note that this field could be 16 bits on x86 ... ;) * * Architectures with slow multiplication can define * WANT_PAGE_VIRTUAL in asm/page.h */#if defined(WANT_PAGE_VIRTUAL)void *virtual;//用于高端内存区域中的页,换言之,即无法直接映射到内核内存中的页,virtual用于存储该页的虚拟地址。#endif /* WANT_PAGE_VIRTUAL */};上述结构中使用了大量的union结构,考虑一个例子:一个物理内存页能够通过多个地方的不同页表映射到虚拟地址空间,内核想要跟踪有多少地方映射了该页,为此,struct page中有一个计数器用于计算映射的数目。如果一页用于slab分配器(后面的博客会详细介绍),那么可以确保只有内核会使用该页,而不会有其它地方使用,因此映射计数信息就是多余的,因此内核可以重新解释该字段,用来表示该页被细分为多少个小的内存对象使用,联合体就很适用于该问题。
- Linux内存管理中内存的组织及主要数据结构分析(pg_data_t&&page&&zone)
- Linux内存管理中内存的组织及主要数据结构分析(pg_data_t&&page&&zone)
- 关于linux内存管理的主要数据结构
- linux内存管理之zone
- linux内核中内存管理数据结构关系及机制(原题:linux虚拟内存组织结构浅析)
- Linux kernel 内存管理重要数据结构关系组织图
- linux内存管理中的page
- linux内存管理数据结构
- Linux内核中内存管理相关的数据结构
- linux内存管理重要的数据结构
- Linux内存管理数据结构之间的关系
- Linux 内存管理分析
- Linux memory management,内核高端内存及各Zone介绍
- linux内核源码分析(内存管理)--之数据结构
- linux内存管理之数据结构
- linux kernel内存管理数据结构
- Linux内存描述之内存区域zone--Linux内存管理(三)
- Linux 内存中Page cache和buffer cache 的区别
- NSMutableAttributedString && NSAttributedString
- SQL2008清除日志文件脚本
- LeetCode[389]Find the Difference
- String与StringBuffer的区别
- php7编译安装
- Linux内存管理中内存的组织及主要数据结构分析(pg_data_t&&page&&zone)
- cout输出16进制
- git命令大全
- C#中使用listview的checkBoxs全选和取消全选
- 占位
- javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building f
- 占位
- iOS App从零搭建
- 占位


