为什么算法渐进复杂度中对数的底数总为2
来源:互联网 发布:中国新歌声 台湾 知乎 编辑:程序博客网 时间:2024/06/11 06:18
本文转载自为什么算法渐进复杂度中对数的底数总为2
在分析各种算法时,经常看到O(log2n)或O(nlog2n)这样的渐进复杂度。不知道有没有同学困惑过,为什么算法的渐进复杂度中的对数都是以2为底?为什么没有见过O(nlog3n)这样的渐进复杂度?本文解释这个问题。先看一个小例子。大多数人应该对归并排序很熟悉,它的渐进复杂度为O(nlog2n)。那么如果我们将归并排序改为均分成三份而不是两份,其算法时间复杂度是否有变化呢?下面通过递归分析对三分式归并排序的时间复杂度进行分析。因为不管是三分还是二分,对于总共n个数据来说,一遍合并的复杂度为O(n),所以三分式归并排序的递归式为:T(n)=3T(n/3)+O(n)。如果把这个递归式的递归树画出来,很容易得到T(n)=O(nlog3n)。
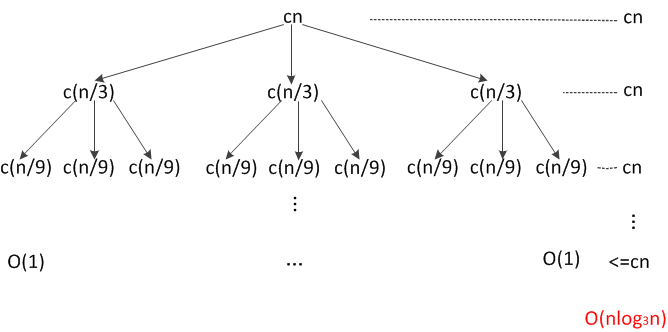
那么这是否意味着三分式归并排序在时间复杂度上要优于二分式的归并排序呢?因为直觉上nlog3n比nlog2n要优一些。实际上三分式归并排序的时间复杂度确实是T(n)=O(nlog3n),而且同时也是T(n)=O(nlog2n)。这看起来似乎是矛盾的,nlog3n和nlog2n当然在绝大多数情况下是不相等的,但是在渐进复杂度情况下就不同了,因为渐进复杂度是忽略常系数的,但是似乎也看不出来nlog3n和nlog2n是差一个常系数。关键就在于我们应该在中学学过的对数换底公式,logab=logcb/logca,其中a和c均大于0且不等于1。根据换底公式可以得log3n=log2n/log23只差一个常系数log23。因此,从渐进时间复杂度看,三分式归并并不比二分式归并更优,当然还是有个常系数的差别的。更一般的,logan=log2n/log2a,因此对于大于1的a来说,都与O(log2n)差一个常系数而已,因此为了简便,一般都用O(log2n)表示对数的渐进复杂度,这就解决了本文初始的疑问。当然,以任何大于1的a为底数都是没有问题的。
- 为什么算法渐进复杂度中对数的底数总为2
- 为什么算法渐进复杂度中对数的底数总为2
- 为什么算法渐进复杂度中对数的底数总为2
- 算法时间复杂度中O(logN)的底数是多少
- 对数复杂度的聚集算法
- 算法 时间复杂度 logN 底数
- 为什么红黑树的时间复杂度为lgn——渐进边界的证明
- 自然对数底数的小数部分二千位
- 自然对数底数e的由来
- 自然对数底数e的由来
- 算法复杂度中的O(logN)底数是多少
- 求逆序对数的一种时间复杂度为nlgn的算法
- 算法分析基础---渐进复杂度
- 算法时间复杂度的表达-渐进符号与主定理
- 排序算法的时间复杂度(总)
- 自然对数的底数e的由来和计算方法
- 求任意底数和任意真数的对数
- 算法时间复杂度-对数阶
- Broadcast学习笔记
- OpenGL 法线自动规范化
- 线程和同步问题
- cache源码分析二 读写逻辑分析
- IllegalArgumentException: Unable to locate adbAndroid
- 为什么算法渐进复杂度中对数的底数总为2
- SSH登陆慢的问题
- css3表达式得到焦点即失去焦点
- Lucene创建索引入门案例
- eventsystem源码分析 多线程框架
- hiho第二十四周
- cache源码分析三 evacuate机制的实现
- Android利用tcpdump和wireshark抓取网络数据包
- cache源码分析四 初始化与元数据同步


