【白书之路】1584 - Circular Sequence 最小字典序
来源:互联网 发布:文明6 mac 中文 编辑:程序博客网 时间:2024/06/11 20:13
1584 - Circular Sequence
Some DNA sequences exist in circular forms as in the following figure, which shows a circular sequence ``CGAGTCAGCT", that is, the last symbol ``T" in ``CGAGTCAGCT" is connected to the first symbol ``C". We always read a circular sequence in the clockwise direction.
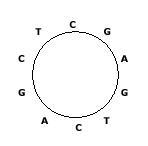
Since it is not easy to store a circular sequence in a computer as it is, we decided to store it as a linear sequence. However, there can be many linear sequences that are obtained from a circular sequence by cutting any place of the circular sequence. Hence, we also decided to store the linear sequence that is lexicographically smallest among all linear sequences that can be obtained from a circular sequence.
Your task is to find the lexicographically smallest sequence from a given circular sequence. For the example in the figure, the lexicographically smallest sequence is ``AGCTCGAGTC". If there are two or more linear sequences that are lexicographically smallest, you are to find any one of them (in fact, they are the same).
Input
The input consists of T test cases. The number of test cases T is given on the first line of the input file. Each test case takes one line containing a circular sequence that is written as an arbitrary linear sequence. Since the circular sequences are DNA sequences, only four symbols, A, C, G and T, are allowed. Each sequence has length at least 2 and at most 100.
Output
Print exactly one line for each test case. The line is to contain the lexicographically smallest sequence for the test case.
The following shows sample input and output for two test cases.
Sample Input
2 CGAGTCAGCT CTCC
Sample Input
AGCTCGAGTC CCCT求一个串的所有循环串中字典序最小的那个串。
先来说一下什么是最小字典序,假设有两个串ABCD,ACBD,那么第一个串的字典序要比第二个小,比较的方法就是从左往右以此比较字符,直到出现字符不相等,字符大的串其字典序就大。
就本题而言,我们不需要找出一个串的所有组合,只需要找到其循环串,即将这些字符放到一个圆上,从任何一个字符出发都可以找到一个字符序列,我们只要从这些序列中找到字典序最小的即可,可以用strcmp()函数。
#include <iostream>#include <stdio.h>#include <string.h>#define MAX 110using namespace std;char seq[MAX];char seq_temp[MAX];char seq_min[MAX];int len;void get_str(){ int i,j; memcpy(seq_min,seq,sizeof(seq)); for(i=0;i<len;i++) { for(j=0;j<len;j++)//枚举所有的循环串 { seq_temp[j]=seq[(j+i)%len]; } //printf("%s\n",seq_temp); if(strcmp(seq_min,seq_temp)>0)//比较字典序 memcpy(seq_min,seq_temp,sizeof(seq)); } printf("%s\n",seq_min);}int main(){ int t; scanf("%d",&t); while(t--) { memset(seq_min,'\0',sizeof(seq_min));//初始化 memset(seq_temp,'\0',sizeof(seq_temp)); scanf("%s",seq); len=strlen(seq); get_str(); } return 0;}- 【白书之路】1584 - Circular Sequence 最小字典序
- UVa 1584 Circular Sequence(环形串最小字典序)
- UVA 1584 Circular Sequence【字典序】
- uva 1584 Circular Sequence(环状串的最小字典序表示法)
- UVa 1584 Circular Sequence(循环串 字典序)
- UVA 1584 - Circular Sequence(环状序列)(字典序)
- Uva1584-环状序列-Circular Sequence-字典序
- UVA 1584 Circular Sequence【串的最小循环表示】
- UVa 1584 Circular Sequence
- UVa 1584 - Circular Sequence
- UVA 1584 - Circular Sequence
- UVA - 1584 Circular Sequence
- UVa 1584 - Circular Sequence
- UVa-1584Circular Sequence
- 1584—Circular Sequence
- 【Uva 1584】 Circular Sequence
- UVa 1584 - Circular Sequence
- UVA 1584 Circular Sequence
- ac自动机模板-kuangbin
- GCD深入理解
- 泰森多边形(Voronoi图)生成算法
- B树、B-树、B+树、B*树都是什么
- 通过VisualSVN的POST-COMMIT钩子自动部署代码
- 【白书之路】1584 - Circular Sequence 最小字典序
- $GLOBALS['HTTP_RAW_POST_DATA'] 和$_POST的区别
- 8张图理解Java
- 【LeetCode】Roman to Integer 解题报告
- 有关sizeof strlen typedef define的面试题
- 使用FTP(IOS FTP客户端开发教程)
- .tar.gz和.rpm包的区别与使用
- 【more effective c++读书笔记】【第5章】技术(3)——要求(或禁止)对象产生于heap之中
- 【Spring MVC】Spring MVC启动过程源码分析


