Hadoop MapReduce 二次排序原理及其应用
来源:互联网 发布:淘宝客服专员岗位职责 编辑:程序博客网 时间:2024/06/11 18:56
目录[-]
关于二次排序主要涉及到这么几个东西:
在0.20.0 以前使用的是
setPartitionerClass
setOutputkeyComparatorClass
setOutputValueGroupingComparator
在0.20.0以后使用是
job.setPartitionerClass(Partitioner p);
job.setSortComparatorClass(RawComparator c);
job.setGroupingComparatorClass(RawComparator c);
下面的例子里面只用到了 setGroupingComparatorClass
mr自带的例子中的源码SecondarySort,我重新写了一下,基本没变。
这个例子中定义的map和reduce如下,关键是它对输入输出类型的定义:(java泛型编程)
public static class Map extends Mapper<LongWritable, Text, IntPair, IntWritable>
public static class Reduce extends Reducer<IntPair, NullWritable, IntWritable, IntWritable>
1、首先说一下工作原理:
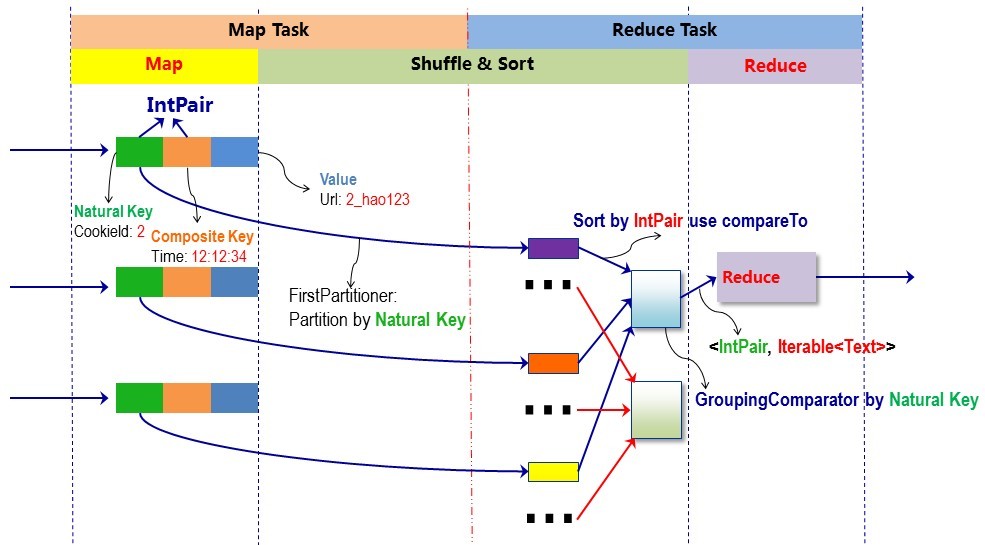
在map阶段,使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。本例子中使用的是TextInputFormat,他提供的RecordReder会将文本的字节偏移量作为key,这一行的文本作为value。这就是自定义Map的输入是<LongWritable, Text>的原因。然后调用自定义Map的map方法,将一个个<LongWritable, Text>对输入给Map的map方法。注意输出应该符合自定义Map中定义的输出<IntPair, IntWritable>。最终是生成一个List<IntPair, IntWritable>。在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。可以看到,这本身就是一个二次排序。 如果没有通过job.setSortComparatorClass设置key比较函数类,则使用key的实现的compareTo方法。 在第一个例子中,使用了IntPair实现的compareTo方法,而在下一个例子中,专门定义了key比较函数类。在reduce阶段,reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass设置的key比较函数类对所有数据对排序。然后开始构造一个key对应的value迭代器。这时就要用到分组,使用jobjob.setGroupingComparatorClass设置的分组函数类。只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,而这个迭代器的key使用属于同一个组的所有key的第一个key。最后就是进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器)。同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
2、二次排序
就是首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序,注意不能破坏第一次排序 的结果 。例如 :
echo "3 b
1 c
2 a
1 d
3 a"|sort -k1 -k2
1 c
1 d
2 a
3 a
3 b
3、具体步骤:
1 自定义key。
在mr中,所有的key是需要被比较和排序的,并且是二次,先根据partitione,再根据大小。而本例中也是要比较两次。先按照第一字段排序,然后再对第一字段相同的按照第二字段排序。根据这一点,我们可以构造一个复合类IntPair,他有两个字段,先利用分区对第一字段排序,再利用分区内的比较对第二字段排序。所有自定义的key应该实现接口WritableComparable,因为是可序列的并且可比较的。并重载方法
//反序列化,从流中的二进制转换成IntPair
public void readFields(DataInput in) throws IOException
//序列化,将IntPair转化成使用流传送的二进制
public void write(DataOutput out)
//key的比较
public int compareTo(IntPair o)
另外新定义的类应该重写的两个方法
//The hashCode() method is used by the HashPartitioner (the default partitioner in MapReduce)
public int hashCode()
public boolean equals(Object right)
2 由于key是自定义的,所以还需要自定义一下类:
2.1 分区函数类。这是key的第一次比较。
public static class FirstPartitioner extends Partitioner<IntPair,IntWritable>在job中设置使用setPartitionerClasss
2.2 key比较函数类。这是key的第二次比较。这是一个比较器,需要继承WritableComparator。
public static class KeyComparator extends WritableComparator
必须有一个构造函数,并且重载 public int compare(WritableComparable w1, WritableComparable w2)
另一种方法是 实现接口RawComparator。
在job中设置使用setSortComparatorClass。
2.3 分组函数类。在reduce阶段,构造一个key对应的value迭代器的时候,只要first相同就属于同一个组,放在一个value迭代器。这是一个比较器,需要继承WritableComparator。
public static class GroupingComparator extends WritableComparator
同key比较函数类,必须有一个构造函数,并且重载 public int compare(WritableComparable w1, WritableComparable w2)
同key比较函数类,分组函数类另一种方法是实现接口RawComparator。
在job中设置使用setGroupingComparatorClass。
另外注意的是,如果reduce的输入与输出不是同一种类型,则不要定义Combiner也使用reduce,因为Combiner的输出是reduce的输入。除非重新定义一个Combiner。
4 代码:
这个例子中没有使用key比较函数类,而是使用key的实现的compareTo方法:
001package SecondarySort;002 003import java.io.DataInput;004import java.io.DataOutput;005import java.io.IOException;006import org.apache.hadoop.conf.Configuration;007import org.apache.hadoop.fs.FileSystem;008import org.apache.hadoop.fs.Path;009import org.apache.hadoop.io.LongWritable;010import org.apache.hadoop.io.Text;011import org.apache.hadoop.io.WritableComparable;012import org.apache.hadoop.io.WritableComparator;013import org.apache.hadoop.mapreduce.Job;014import org.apache.hadoop.mapreduce.Mapper;015import org.apache.hadoop.mapreduce.Partitioner;016import org.apache.hadoop.mapreduce.Reducer;017import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;018import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;019import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;020import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;021 022public class SecondarySort023{024 //自己定义的key类应该实现WritableComparable接口025 public static class IntPair implements WritableComparable<IntPair>026 {027 String first;028 String second;029 /**030 * Set the left and right values.031 */032 public void set(String left, String right)033 {034 first = left;035 second = right;036 }037 public String getFirst()038 {039 return first;040 }041 public String getSecond()042 {043 return second;044 }045 //反序列化,从流中的二进制转换成IntPair046 public void readFields(DataInput in) throws IOException047 {048 first = in.readUTF();049 second = in.readUTF();050 }051 //序列化,将IntPair转化成使用流传送的二进制052 public void write(DataOutput out) throws IOException053 {054 out.writeUTF(first);055 out.writeUTF(second);056 }057 //重载 compareTo 方法,进行组合键 key 的比较,该过程是默认行为。058 //分组后的二次排序会隐式调用该方法。059 public int compareTo(IntPair o)060 {061 if (!first.equals(o.first) )062 {063 return first.compareTo(o.first);064 }065 else if (!second.equals(o.second))066 {067 return second.compareTo(o.second);068 }069 else070 {071 return 0;072 }073 }074 075 //新定义类应该重写的两个方法076 //The hashCode() method is used by the HashPartitioner (the default partitioner in MapReduce)077 public int hashCode()078 {079 return first.hashCode() * 157 + second.hashCode();080 }081 public boolean equals(Object right)082 {083 if (right == null)084 return false;085 if (this == right)086 return true;087 if (right instanceof IntPair)088 {089 IntPair r = (IntPair) right;090 return r.first.equals(first) && r.second.equals(second) ;091 }092 else093 {094 return false;095 }096 }097 }098 /**099 * 分区函数类。根据first确定Partition。100 */101 public static class FirstPartitioner extends Partitioner<IntPair, Text>102 {103 public int getPartition(IntPair key, Text value,int numPartitions)104 {105 return Math.abs(key.getFirst().hashCode() * 127) % numPartitions;106 }107 }108 109 /**110 * 分组函数类。只要first相同就属于同一个组。111 */112 /*//第一种方法,实现接口RawComparator113 public static class GroupingComparator implements RawComparator<IntPair> {114 public int compare(IntPair o1, IntPair o2) {115 int l = o1.getFirst();116 int r = o2.getFirst();117 return l == r ? 0 : (l < r ? -1 : 1);118 }119 //一个字节一个字节的比,直到找到一个不相同的字节,然后比这个字节的大小作为两个字节流的大小比较结果。120 public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2){121 return WritableComparator.compareBytes(b1, s1, Integer.SIZE/8,122 b2, s2, Integer.SIZE/8);123 }124 }*/125 //第二种方法,继承WritableComparator126 public static class GroupingComparator extends WritableComparator127 {128 protected GroupingComparator()129 {130 super(IntPair.class, true);131 }132 //Compare two WritableComparables.133 // 重载 compare:对组合键按第一个自然键排序分组134 public int compare(WritableComparable w1, WritableComparable w2)135 {136 IntPair ip1 = (IntPair) w1;137 IntPair ip2 = (IntPair) w2;138 String l = ip1.getFirst();139 String r = ip2.getFirst();140 return l.compareTo(r);141 }142 }143 144 145 // 自定义map146 public static class Map extends Mapper<LongWritable, Text, IntPair, Text>147 {148 private final IntPair keyPair = new IntPair();149 String[] lineArr = null;150 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException151 {152 String line = value.toString();153 lineArr = line.split("\t", -1);154 keyPair.set(lineArr[0], lineArr[1]);155 context.write(keyPair, value);156 }157 }158 // 自定义reduce159 //160 public static class Reduce extends Reducer<IntPair, Text, Text, Text>161 {162 private static final Text SEPARATOR = new Text("------------------------------------------------");163 164 public void reduce(IntPair key, Iterable<Text> values,Context context) throws IOException, InterruptedException165 {166 context.write(SEPARATOR, null);167 for (Text val : values)168 {169 context.write(null, val);170 }171 }172 }173 174 public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException175 {176 // 读取hadoop配置177 Configuration conf = new Configuration();178 // 实例化一道作业179 Job job = new Job(conf, "secondarysort");180 job.setJarByClass(SecondarySort.class);181 // Mapper类型182 job.setMapperClass(Map.class);183 // 不再需要Combiner类型,因为Combiner的输出类型<Text, IntWritable>对Reduce的输入类型<IntPair, IntWritable>不适用184 //job.setCombinerClass(Reduce.class);185 // Reducer类型186 job.setReducerClass(Reduce.class);187 // 分区函数188 job.setPartitionerClass(FirstPartitioner.class);189 // 分组函数190 job.setGroupingComparatorClass(GroupingComparator.class);191 192 // map 输出Key的类型193 job.setMapOutputKeyClass(IntPair.class);194 // map输出Value的类型195 job.setMapOutputValueClass(Text.class);196 // rduce输出Key的类型,是Text,因为使用的OutputFormatClass是TextOutputFormat197 job.setOutputKeyClass(Text.class);198 // rduce输出Value的类型199 job.setOutputValueClass(Text.class);200 201 // 将输入的数据集分割成小数据块splites,同时提供一个RecordReder的实现。202 job.setInputFormatClass(TextInputFormat.class);203 // 提供一个RecordWriter的实现,负责数据输出。204 job.setOutputFormatClass(TextOutputFormat.class);205 206 // 输入hdfs路径207 FileInputFormat.setInputPaths(job, new Path(args[0]));208 // 输出hdfs路径209 FileSystem.get(conf).delete(new Path(args[1]), true);210 FileOutputFormat.setOutputPath(job, new Path(args[1]));211 // 提交job212 System.exit(job.waitForCompletion(true) ? 0 : 1);213 }214}5 测试需求:
假如我们现在的需求是先按 cookieId 排序,然后按 time 排序,以便按 session 切分日志
6 测试数据与结果:
01cookieId time url022 12:12:34 2_hao123033 09:10:34 3_baidu041 15:02:41 1_google053 22:11:34 3_sougou061 19:10:34 1_baidu072 15:02:41 2_google081 12:12:34 1_hao123093 23:10:34 3_soso102 05:02:41 2_google11 12结果:13------------------------------------------------141 12:12:34 1_hao123151 15:02:41 1_google161 19:10:34 1_baidu17------------------------------------------------182 05:02:41 2_google192 12:12:34 2_hao123202 15:02:41 2_google21------------------------------------------------223 09:10:34 3_baidu233 22:11:34 3_sougou243 23:10:34 3_soso7 原理图(点击查看大图):
8、推荐阅读:
hive中使用标准sql实现分组内排序
http://superlxw1234.iteye.com/blog/1869612
Pig、Hive、MapReduce 解决分组 Top K 问题
http://my.oschina.net/leejun2005/blog/85187
9、REF:
mapreduce的二次排序 SecondarySort
http://blog.csdn.net/zyj8170/article/details/7530728
学会定制MapReduce里的partition,sort和grouping,Secondary Sort Made Easy 进行二次排序
http://blog.sina.com.cn/s/blog_9bf980ad0100zk7r.html
Simple Moving Average, Secondary Sort, and MapReduce (Part 3)
http://blog.cloudera.com/blog/2011/04/simple-moving-average-secondary-sort-and-mapreduce-part-3/
https://github.com/jpatanooga/Caduceus/tree/master/src/tv/floe/caduceus/hadoop/movingaverage
MapReduce的排序和二次排序原理总结
http://hugh-wangp.iteye.com/blog/1491175
泛型value的二次排序
http://wenku.baidu.com/view/a3826a235901020207409c47.html
http://vangjee.wordpress.com/2012/03/20/secondary-sorting-aka-sorting-values-in-hadoops-mapreduce-programming-paradigm/
转自:http://my.oschina.net/leejun2005/blog/132785
- Hadoop MapReduce 二次排序原理及其应用
- Hadoop MapReduce 二次排序原理及其应用
- Hadoop MapReduce 二次排序原理及其应用
- Hadoop MapReduce 二次排序
- mapreduce(七):hadoop二次排序
- 【Hadoop】MapReduce温度排序之二次排序
- hadoop mapreduce排序原理
- Hadoop MapReduce 深入理解!二次排序案例!
- hadoop之MapReduce练习-二次排序
- MapReduce/Hadoop的二次排序解决方案
- MapReduce之二次排序类应用
- Hadoop---mapreduce排序和二次排序以及全排序
- Hadoop二次排序及MapReduce处理流程实例详解
- Hadoop之MapReduce自定义二次排序流程实例详解
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
- Hadoop之MapReduce自定义二次排序流程实例详解
- Hadoop Mapreduce分区、分组、二次排序过程详解
- (Hadoop学习-2)mapreduce实现二次排序
- 颇有见地却又无意功名,真正是一“痴儿”矣!
- hge 像素碰撞检测 以及 碰撞
- Android资源文件res的使用详解(strings,layout,drawable,arrays等)
- 磨练构建正则表达式模式
- 小米手机数据丢失怎么恢复
- Hadoop MapReduce 二次排序原理及其应用
- 笔记本硬盘数据导出失败怎么恢复
- C#的委托区别 Action,Func, Predicate
- 在MFC中从一个线程工作函数中向窗口发送消息(this指针的妙用) .
- PHP中的$_SERVER["HTTP_REFERER"]用法浅谈
- TCP 传输
- CSS3常用功能的写法
- 您对无法重新创建的表进行了更改或者启用了“阻止保存要求重新创建表的更改”选项
- Reverse Integer


