新浪微博,腾讯微博mysql数据库主表猜想-pull
来源:互联网 发布:徒步鞋 知乎 编辑:程序博客网 时间:2024/06/12 01:20
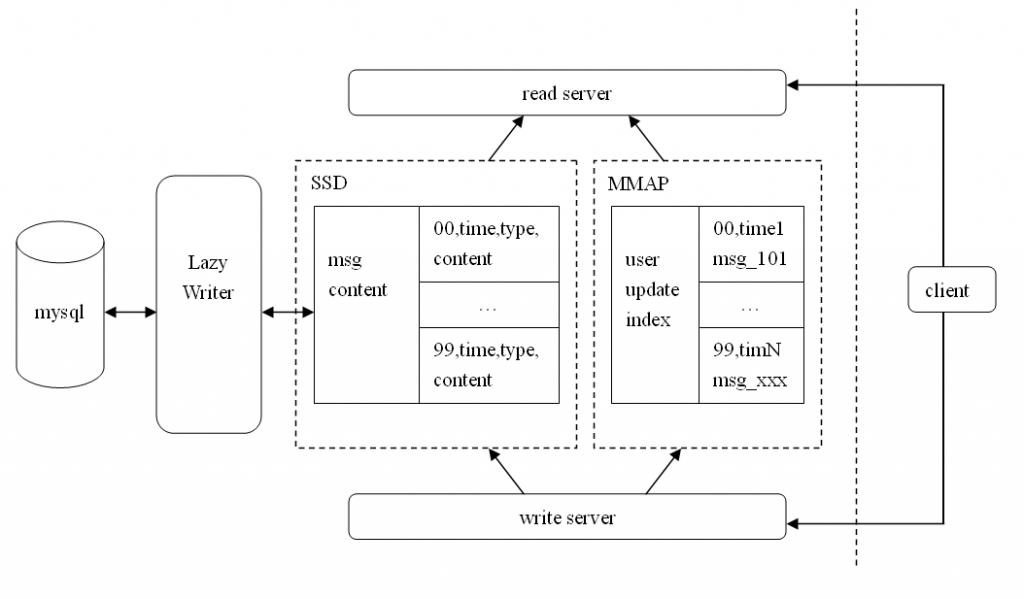
设计要点:
1)DB只作为持久化容器,一切操作在逻辑层完成
2)异步,前端的请求只要在中间server上完成就好,后续的持久化由LazyWriter完成(定时)
3)可以分布式实现,中间逻辑的read和write可是分号段,以适应批量操作,map/reduce
4)尽量做到全量cache,尤其是index
流程说明:
1)在A产生Feed的时候,更新index中A节点的最后更新时间,并标记Feed_id(对于微博来说没有必要做摘要);然后将content等详细记录写入元数据存储空间
2)B(A的粉丝)登录拉取最新Feed时,由于数量限制(首页有显示空间限制,一般都要做成page_index+page_count)只能拉取所有关注对象中最新的N条Feed,这时先通过批量查询对B的所有关注对象最新Feed做一个排序,因为完全在内存中实现,而且可以map/reduce,所以时间消耗很少,在生成了最新的Feed列表后,直接批量向元数据存储空间拉取完成信息
pull模式的实时性比push模式要好,但是也会遇到关注对象太多时拉取慢的情况,无论pull还是push,最后都可以通过cache index实现快速索引的生成,通过map/reduce实现批量请求的分割与快速处理。
作为互联网应用来说,保证最终一致性才是最重要的,另外一点,对逻辑数据分层次处理,做优先级划分
6月1日更新:
本文是pull模式,关于微博的push模式请参见 http://blog.csdn.net/cleanfield/archive/2011/04/21/6339428.aspx
- 新浪微博,腾讯微博mysql数据库主表猜想-pull
- 新浪&腾讯微博:MySQL数据库主表设计猜想
- 新浪&腾讯微博:MySQL数据库主表设计猜想
- 新浪&腾讯微博:MySQL数据库主表设计猜想
- 新浪微博,腾讯微博mysql数据库主表猜想
- 新浪微博,腾讯微博mysql数据库主表猜想
- 新浪微博,腾讯微博mysql数据库主表猜想
- 新浪微博,腾讯微博mysql数据库主表猜想
- 新浪微博,腾讯微博mysql数据库主表猜想
- 新浪微博,腾讯微博mysql数据库主表猜想
- 新浪微博,腾讯微博另一种实现方式--pull
- 新浪微博页面向下pull实现
- 新浪和腾讯微博教程(二)
- 腾讯微博为何拼不过新浪?
- 腾讯微博为何干不过新浪?
- 新浪腾讯微博转发 js代码
- 分享帖子到腾讯、新浪微博
- 新浪微博,腾讯微博,腾讯QQ登录
- 迷宫的最短路径
- 关于浮点数的小常识
- iPhone 开发过程中的一些小技术的总结[转载]
- Android 应用程序开发错误调试问题
- EBS常用表结构
- 新浪微博,腾讯微博mysql数据库主表猜想-pull
- 解决asp.net表单提交按钮当设定OnClientClick事件后不再进行表单验证的问题
- js类成员
- linux 驱动 编译 Makefile
- SQL Server如何清除连接过的服务器名称历史?
- 彻底鄙视
- 流形学习
- .Net常用命名空间介绍
- 嵌入式linux软件开发下的数据参数保存


