hdu 5486 Difference of Clustering(合肥网赛)
来源:互联网 发布:中信淘宝信用卡额度 编辑:程序博客网 时间:2024/06/08 02:37
Difference of Clustering
Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submission(s): 74 Accepted Submission(s): 17
Problem Description
Given two clustering algorithms, the old and the new, you want to find the difference between their results.
A clustering algorithm takes manymember entities as input and partition them into clusters . In this problem, a member entity must be clustered into exactly one cluster. However, we don’t have any pre-knowledge of the clusters, so different algorithms may produce different number of clusters as well as different cluster IDs. One thing we are sure about is that the memberIDs are stable, which means that the same member ID across different algorithms indicates the same member entity.
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
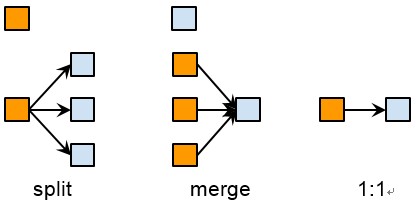
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
A clustering algorithm takes many
To compare two clustering algorithms, we care about three kinds of relationship between the old clusters and the new clusters: split, merge and 1:1. Please refer to the figure below.
Let’s explain them with examples. Say in the old result, m0, m1, m2 are clustered into one cluster c0, but in the new result, m0 and m1 are clustered into c0, but m2 alone is clustered into c1. We denote the relationship like the following:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1], c1 = [m2]
There is no other members in the new c0 and c1. Then we say the old c0 is split into new c0 and new c1. A few more examples:
● In the old, c0 = [m0, m1, m2]
● In the new, c0 = [m0, m1, m2].
This is 1:1.
● In the old, c0 = [m0, m1], c1 = [m2]
● In the new, c0 = [m0, m1, m2]
This is merge. Please note, besides these relationship, there is another kind called “n:n”:
● In the old, c0 = [m0, m1], c1 = [m2, m3]
● In the new, c0 = [m0, m1, m2], c1 = [m3]
We don’t care about n:n.
In this problem, we will give you two sets of clustering results, each describing the old and the new. We want to know the total number of splits, merges, and 1:1 respectively.
Input
The first line of input contains a number T indicating the number of test cases (T≤100 ).
Each test case starts with a line containing an integerN indicating the number of member entities (0≤N≤106 ). In the following N lines, the i -th line contains two integers c1 and c2, which means that the member entity with ID i is partitioned into cluster c1 and cluster c2 by the old algorithm and the new algorithm respectively. The cluster IDs c1 and c2 can always fit into a 32-bit signed integer.
Each test case starts with a line containing an integer
Output
For each test case, output a single line consisting of “Case #X: A B C”. X is the test case number starting from 1. A , B , and C are the numbers of splits, merges, and 1:1s.
Sample Input
230 00 00 140 00 01 11 1
Sample Output
Case #1: 1 0 0Case #2: 0 0 2
解题思路:
首先要离散化,然后将每对old和new建立一条边,重复的边要去掉,并统计每个点的度,于是就会发现1:1的
肯定是这两个顶点度有一条边,并且两个顶点的度都为1,1:n的情况,即split,odd的顶点的度肯定大于1,并且
与之相连的顶点的度都为1,于是solit和1:1的就解决了,再反过来,以new的顶点为边的起点,就可以解决merge
的情况。
代码:
#include<iostream>#include<cstdio>#include<cstring>#include<algorithm>#include<vector>#include<map>using namespace std;struct EDGE{ int to,next; EDGE(int a,int b) { to=a; next=b; }};vector<EDGE> edge;pair<int,int> node[1000010];int du[2000010];int n,ne=0;int num[1000010],num2[1000010];int head[2000010];void addedge(int u,int v){ //cout<<u<<" "<<v<<endl; edge.push_back(EDGE(v,head[u])); // edge[ne].to=v;// edge[ne].next=head[u]; head[u]=ne++;}bool cmp(pair<int,int> a,pair<int,int> b){ if(a.first==b.first) return a.second<b.second; return a.first<b.first;}int uni(){ int len=0; sort(node,node+n,cmp); for(int i=0;i<n;i++) { if(i==n-1||node[i].first!=node[i+1].first||node[i].second!=node[i+1].second) node[len++]=node[i]; } return len;}int main(){ // freopen("D:\\in.txt","r",stdin); int T,i,j,cnt=1; cin>>T; while(T--) { memset(du,0,sizeof(du)); ne=0; edge.clear(); memset(head,-1,sizeof(head)); cin>>n; for(i=0;i<n;i++) { scanf("%d %d",&node[i].first,&node[i].second); num[i]=node[i].first; num2[i]=node[i].second; } sort(num,num+n); sort(num2,num2+n); int len=unique(num,num+n)-num; int len2=unique(num2,num2+n)-num2; map<int,int> lst,lst2; for(i=1;i<=len;i++) lst[num[i-1]]=i; for(i=1;i<=len2;i++) lst2[num2[i-1]]=i+len; int len3=uni(); for(i=0;i<len3;i++) { int x=lst[node[i].first],y=lst2[node[i].second]; // cout<<x<<" "<<y<<endl; du[x]++,du[y]++; addedge(x,y); addedge(y,x); } //cout<<"ok\n"; int ans1=0,ans2=0,ans3=0; for(i=1;i<=len;i++) { if(du[i]==1) { int to=edge[head[i]].to; // cout<<to<<endl; if(du[to]==1) ans3++; } else if(du[i]>1) { int flag=1; for(int t=head[i];t!=-1;t=edge[t].next) { if(du[edge[t].to]>1) { flag=0; break; } } // cout<<flag<<" "<<i<<endl; if(flag) ans1++; } } for(i=len+1;i<=len+len2;i++) { if(du[i]>1) { int flag=1; for(int t=head[i];t!=-1;t=edge[t].next) { if(du[edge[t].to]>1) { flag=0; break; } } if(flag) ans2++; } } printf("Case #%d: %d %d %d\n",cnt++,ans1,ans2,ans3); }} 0 0
- hdu 5486 Difference of Clustering(合肥网赛)
- hdu 5486 Difference of Clustering 2015合肥网络赛 并查集 离散化 悲伤的题
- hdu 5486 Difference of Clustering
- hdu 5486 Difference of Clustering
- HDU 5486(Difference of Clustering-聚类)
- hdu 5486 Difference of Clustering(暴力)
- HDU 5486 Difference of Clustering 图论
- hdu 5486 Difference of Clustering 2015多校联合训练赛
- HDU5486-Difference of Clustering
- HDU 5561 【2015合肥现场赛】 Kingdom of Tree
- hdu 5487 Difference of Languages(bfs)
- hdu 5487 Difference of Languages BFS
- hdu 5487 Difference of Languages BFS
- HDU 5493 Queue (合肥网络赛 1010 )
- hdu 5491 The Next(ICPC合肥赛)
- HDU 5493 Queue (树状数组+二分)2015 ICPC 合肥网赛
- HDU 5491 The Next (二进制) 2015合肥网络赛
- HDU 5489 Removed Interval (合肥网络赛 1006 )
- HDU 5492 Find a path(DP)——2015 ACM/ICPC Asia Regional Hefei Online
- Java编程【2】 -getFlyAnimal() ->accept an animal list,and return an animal list which contains only anim
- 上下拉刷新之第三方库MJRefresh 的具体使用——(用于UITabView的数据刷新)
- 软考教程复习上
- leetcode11 Container With Most Water
- hdu 5486 Difference of Clustering(合肥网赛)
- UVa 12611 - Beautiful Flag
- Java学习目录(初级篇)
- HDU 4333 Revolving Digits(扩展KMP啊)
- hdu-5481 Desiderium
- java inetAddress类,URL类
- LintCode -- k数和
- Server Tomcat v7.0 Server at localhost was unable to start within 45 seconds
- Ubuntu 远程配置 openfire


